在oracle中插入
使用pl/sql developer数据生成器
报错ORA-01653
表空间扩展失败,参考http://www.2cto.com/database/201201/116522.html 解决方法
alter tablespace USERS
add datafile '/u01/app/oracle/oradata/XE/users2.dbf' size 10240M;
报错ORA-12953
超过了允许的最大数据库大小。原因是oracle11g xe版本只支持11g大小用户空间。 解决方法,暂无。
在mongodb中插入
编写程序模拟数据,采用insert batch操作,每10000条数据一插。对于某些可能有意义的字段采用了枚举,枚举数目为10个。
报错
第一次在2363万条数据时报错
Exception in thread "main" org.springframework.dao.DataAccessResourceFailureException: Operation on server 114.212.189.143:27017 failed; nested exception is com.mongodb.MongoException$Network: Operation on server 114.212.189.143:27017 failed
第二次在7000多万条时报错。查看数据库,发现只有4000多万数据。我当时怀疑可能mongodb的insert操作是异步的,导致了大量insert堆积,最后丢失数据。 我决定再插一次,如果还不成功,就分多次插。然而这次容器崩溃了。
容器崩溃
shard1和router崩溃了,重启无效。删除容器后新建也无效。 一开始我怀疑是镜像坏掉了,于是使用袁忠良配过的另一个镜像,那个镜像需要手动启动数据库。手动启动的时候报错journal大小不足3g,无法启动数据库。于是查看,发现服务器存储空间已经耗竭。 解决方法,暂无,目前先插入5000万条数据。
 然后分别编辑输入输出,编辑oracle数据库:
然后分别编辑输入输出,编辑oracle数据库:
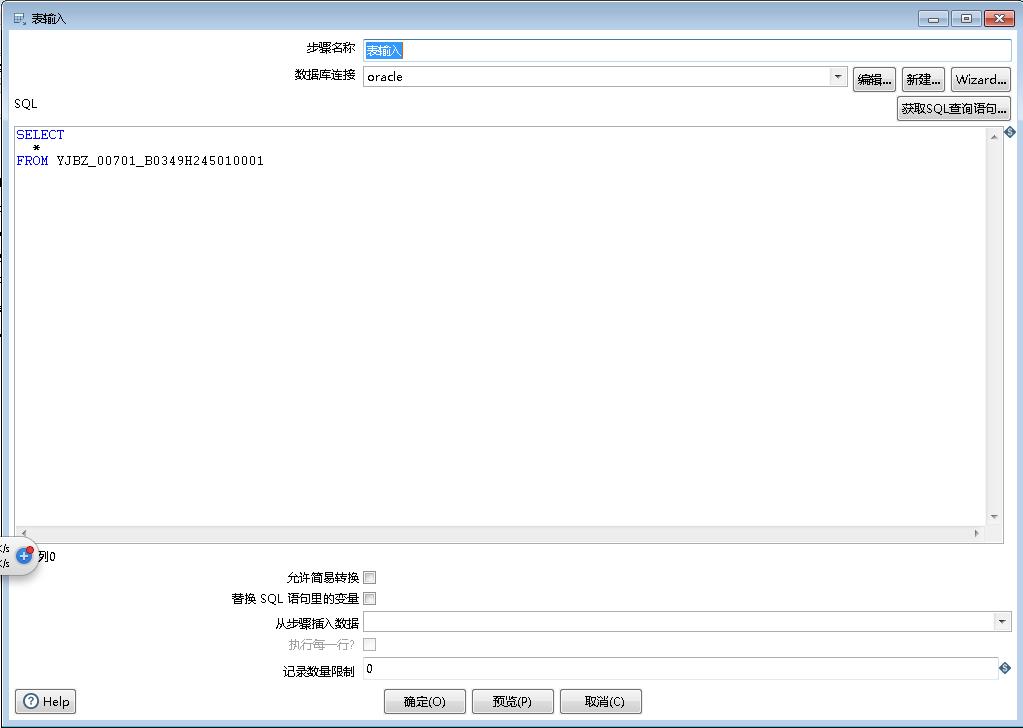 编辑mongoDB数据库:
编辑mongoDB数据库:
 一开始我以为是mongodb的cursor关闭了,因为看文档说mongodb的cursor默认十分钟关闭,而spoon迁移大概10分钟的时候停了。因为spoon没有改相关项的选项,所以后来打算自己写程序,然而自己写程序后,发现用不到mongodb的cursor。而且也在83万多数据的时候出问题,卡住不动了。
后来可能的原因是数据一次读取过多,因为2次出错读取的数据差不多多(83万和84万),所以下一步会尝试分多次读取数据,比如50万数据一读。
最后找到问题了,是mongodb32位存储空间不足,解决方法是在远程服务器上运行64位mongodb。迁移用时约38分钟。
一开始我以为是mongodb的cursor关闭了,因为看文档说mongodb的cursor默认十分钟关闭,而spoon迁移大概10分钟的时候停了。因为spoon没有改相关项的选项,所以后来打算自己写程序,然而自己写程序后,发现用不到mongodb的cursor。而且也在83万多数据的时候出问题,卡住不动了。
后来可能的原因是数据一次读取过多,因为2次出错读取的数据差不多多(83万和84万),所以下一步会尝试分多次读取数据,比如50万数据一读。
最后找到问题了,是mongodb32位存储空间不足,解决方法是在远程服务器上运行64位mongodb。迁移用时约38分钟。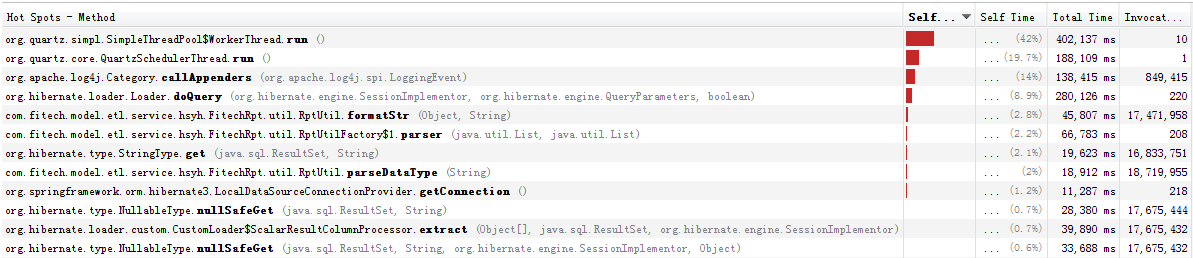 这是失去响应之前的截图
第一位是org.quartz.simpl.SimpleThreadPool$WorkerThread.run()
第二位是org.quartz.core.QuartzSchedulerThread.run()
第三位是org.apache.log4j.Category.callAppenders(org.apache.log4j.spi.LoggingEvent)
第四位是org.hibernate.loader.Loader.doQuery(org.hibernate.engine.SessionImplementor, org.hibernate.engine.QueryParameters, boolean)
从第五位开始数值就很小了。
这是失去响应之前的截图
第一位是org.quartz.simpl.SimpleThreadPool$WorkerThread.run()
第二位是org.quartz.core.QuartzSchedulerThread.run()
第三位是org.apache.log4j.Category.callAppenders(org.apache.log4j.spi.LoggingEvent)
第四位是org.hibernate.loader.Loader.doQuery(org.hibernate.engine.SessionImplementor, org.hibernate.engine.QueryParameters, boolean)
从第五位开始数值就很小了。
 共有2段,将192.168.0.89:1521:orcl修改为localhost:1521:xe
共有2段,将192.168.0.89:1521:orcl修改为localhost:1521:xe 程序入口,ETLConductExportService处理主要内容。
程序入口,ETLConductExportService处理主要内容。 主要功能在方法writerUploadFile中实现,由于采用oracle数据库,调用createRptFile生成报文。
主要功能在方法writerUploadFile中实现,由于采用oracle数据库,调用createRptFile生成报文。 全部报文,调用方法creRptFileAll
全部报文,调用方法creRptFileAll 调用方法creRpfFileSgl
调用方法creRpfFileSgl


 每10000行创建一个新的线程,线程RptExpOprThread用来生成报文。
每10000行创建一个新的线程,线程RptExpOprThread用来生成报文。 调用方法createSplitRpt
调用方法createSplitRpt 调用方法createRptFile
调用方法createRptFile
 生成报文文件
生成报文文件