com/fitech/model/etl/service/hsyh/ETLConductExportService.java:56
from EtlTaskInfo e where e.taskId= 61
表ETL_TASK_INFO
com/fitech/model/etl/service/hsyh/ETLConductExportService.java:59
select config_value from east.sys_config where config_key='need_hand_export'
表SYS_CONFIG
com/fitech/model/etl/service/hsyh/ETLConductExportService.java:68
select base_rpt_id,model_name,main_type,rpt_en_name from east.base_rpt_info where rpt_name='交易流水'
表BASE_RPT_INFO
com/fitech/model/etl/service/hsyh/ETLConductExportService.java:73
select count(0) from east.YJBZ_00701_B0349H245010001
表YJBZ_00701_B0349H245010001
com/fitech/model/etl/service/hsyh/ETLConductExportService.java:78
delete from east.YJBZ_ETL_CHECK where TASK_NAME='交易流水' and TERM='20141231'
表YJBZ_ETL_CHECK
com/fitech/model/etl/service/hsyh/ETLConductExportService.java:108
insert into east.convert_log(log_name,log_message,log_time,log_term) values (?,?,?,?)
表CONVERT_LOG
com/fitech/model/etl/service/hsyh/FitechRpt/service/impl/RptOprServiceImpl.java:248
SELECT FIELD_EN_NAME,FIELD_TYPE FROM east.BASE_FIELD_INFO FIELD_INFO WHERE FIELD_INFO.BASE_RPT_ID = 'yjbz_00701' ORDER BY FIELD_INFO.ORDER_ID ASC
表BASE_FIELD_INFO
com/fitech/model/etl/service/hsyh/FitechRpt/service/impl/RptOprServiceImpl.java:269
select count(1) from east.YJBZ_00701_B0349H245010001
表YJBZ_00701_B0349H245010001
com\fitech\model\etl\service\hsyh\FitechRpt\util\RptUtil.java:438
select HXJYLSH,ZJYLSH,BCXH,JYRQ,YXJGDM,NBJGH,JRXKZH,MXKMBH,JYSJ,JZRQ,JZSJ,JYJGMC,JYZH,JYHM,JYXTMC,DFXH,DFJGMC,DFZH,DFHM,JYJE,ZHYE,JDBZ,XZBZ,BZ,YWLX,JYLX,JYQD,JYJZMC,JYJZH,CZGYH,GYLSH,FHGYH,ZY,ZPZZL,ZPZH,FPZZL,FPZH,CBMBZ,SJC,ZHBZ,KXHBZ,CJRQ
from YJBZ_00701_B0349H245010001
where num>=begIndex and num <+(begIndex+count)
表YJBZ_00701_B0349H245010001
]]>
 然后分别编辑输入输出,编辑oracle数据库:
然后分别编辑输入输出,编辑oracle数据库:
 编辑mongoDB数据库:
编辑mongoDB数据库:
 一开始我以为是mongodb的cursor关闭了,因为看文档说mongodb的cursor默认十分钟关闭,而spoon迁移大概10分钟的时候停了。因为spoon没有改相关项的选项,所以后来打算自己写程序,然而自己写程序后,发现用不到mongodb的cursor。而且也在83万多数据的时候出问题,卡住不动了。
后来可能的原因是数据一次读取过多,因为2次出错读取的数据差不多多(83万和84万),所以下一步会尝试分多次读取数据,比如50万数据一读。
最后找到问题了,是mongodb32位存储空间不足,解决方法是在远程服务器上运行64位mongodb。迁移用时约38分钟。
一开始我以为是mongodb的cursor关闭了,因为看文档说mongodb的cursor默认十分钟关闭,而spoon迁移大概10分钟的时候停了。因为spoon没有改相关项的选项,所以后来打算自己写程序,然而自己写程序后,发现用不到mongodb的cursor。而且也在83万多数据的时候出问题,卡住不动了。
后来可能的原因是数据一次读取过多,因为2次出错读取的数据差不多多(83万和84万),所以下一步会尝试分多次读取数据,比如50万数据一读。
最后找到问题了,是mongodb32位存储空间不足,解决方法是在远程服务器上运行64位mongodb。迁移用时约38分钟。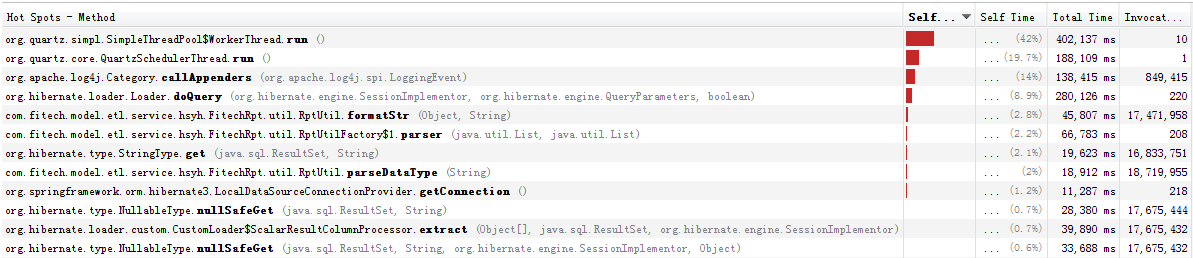 这是失去响应之前的截图
第一位是org.quartz.simpl.SimpleThreadPool$WorkerThread.run()
第二位是org.quartz.core.QuartzSchedulerThread.run()
第三位是org.apache.log4j.Category.callAppenders(org.apache.log4j.spi.LoggingEvent)
第四位是org.hibernate.loader.Loader.doQuery(org.hibernate.engine.SessionImplementor, org.hibernate.engine.QueryParameters, boolean)
从第五位开始数值就很小了。
这是失去响应之前的截图
第一位是org.quartz.simpl.SimpleThreadPool$WorkerThread.run()
第二位是org.quartz.core.QuartzSchedulerThread.run()
第三位是org.apache.log4j.Category.callAppenders(org.apache.log4j.spi.LoggingEvent)
第四位是org.hibernate.loader.Loader.doQuery(org.hibernate.engine.SessionImplementor, org.hibernate.engine.QueryParameters, boolean)
从第五位开始数值就很小了。
 共有2段,将192.168.0.89:1521:orcl修改为localhost:1521:xe
共有2段,将192.168.0.89:1521:orcl修改为localhost:1521:xe 程序入口,ETLConductExportService处理主要内容。
程序入口,ETLConductExportService处理主要内容。
 主要功能在方法writerUploadFile中实现,由于采用oracle数据库,调用createRptFile生成报文。
主要功能在方法writerUploadFile中实现,由于采用oracle数据库,调用createRptFile生成报文。 全部报文,调用方法creRptFileAll
全部报文,调用方法creRptFileAll 调用方法creRpfFileSgl
调用方法creRpfFileSgl


 每10000行创建一个新的线程,线程RptExpOprThread用来生成报文。
每10000行创建一个新的线程,线程RptExpOprThread用来生成报文。 调用方法createSplitRpt
调用方法createSplitRpt 调用方法createRptFile
调用方法createRptFile
 生成报文文件
生成报文文件